Let me introduce you today to a package that is quite unknown as you hopefully never need it. But when you need it and have not thought about it before, it is probably already too late. I am talking about „sash“ – the „Stand Alone SHell“. Yet another shell? Yes and no. Yes it is a shell, but no, I am not trying to show something like the shiny friendly interactive shell or (my favorite) „zsh“. Quite the contrary: You can give „sash“ a lot of attributes, but not „shiny“.
So what is about? Imagine the following case: You are running a machine and suddenly something goes totally wrong. Partition errors, missing libraries, you have messed around with libc, whatever. This can get you into serious trouble. You are fine, when you have the possibility to boot a recovery cd or something similar. But under some circumstances you might have to stick to the programs already installed though they seem to be broken. Maybe it is a virtual server somewhere on the web and you are only allowed to boot into a recovery mode giving you a prompt to your server. So you are trying to login as root but it just does not work for some reasons. Broken dependencies. Who knows.
The point is: When you login onto a machine for system recovery, you are already relying on a lot of tools and dependencies – though it only seems to be a shell. The shell might be linked against a couple of libraries, a lot of commands you want to run are not build in and therefore a bunch of external dependencies can bar your way. So what you actually might need in a situation of severe pain is a shell that provides you with as much essential tools as you need on its own without relying on external code.
Installing sash
This is where „sash“ comes into play. Sash is not a dynamic linked executable, it has actually all needed features built in. So as long as you can execute the sash binary, you can have a working shell. Let’s check it! Install „sash“ by using „aptitude install sash“ or you preferred package manager. Please note, that sash will clone your current root account:
cloning root account entry to create sashroot account in /etc/passwd
Cloned sashroot from root in /etc/passwd
cloning root account entry to create sashroot account in /etc/shadow
Cloned sashroot from root in /etc/shadow
So you have this new line in your /etc/passwd:
sashroot:x:0:0:root:/root:/bin/sash
You should consider giving sashroot a password if you want to be able to login with this account. But please check if this applies to your security needs.
See the difference
Now let’s check how the sash binary differs from the standard shell, the bash and the zsh. We are using „ldd“ for this, as it is lists libraries, an executable is linked against:
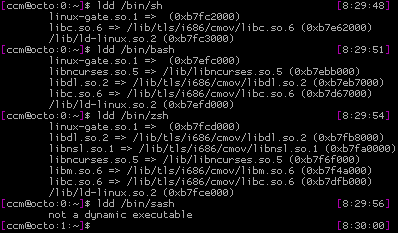
Pretty impressive. All „normal“ shells have at least three dependencies, sash apparently has none.
But getting rid of external libraries is not the only difference sash makes. Another major feature is the collection of built-in commands:
-ar, -chattr, -chgrp, -chmod, -chown, -cmp, -cp,
-dd, -echo, -ed, -grep, -file, -find, -gunzip,
-gzip, -kill, -ln, -ls, -lsattr, -mkdir, -mknod,
-more, -mount, -mv, -printenv, -pwd, -rm, -rmdir,
-sum, -sync, -tar, -touch, -umount, -where
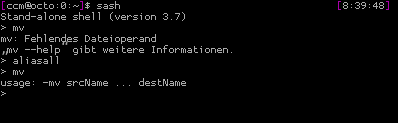
Seems like a list of commands you yearn for, when in recovery mode, don’t you? Note the leading „-“ at the beginning of those commands. This is the way, sash handles your attempts to run internal and external commands. When using „mv“, sash gives you the normal /bin/mv, when using „-mv“, sash provides you with it’s own replacement. But „sash“ helps you when you don’t want to type the „-“ at the beginning of every command. You can enter „aliasall“ in a sash session as it will create non permanent aliases for all builtin commands:
Emergency
In case of an emergency you might need to boot directly into sash as maybe your initrd stuff is broken. How? Just append a „init=/bin/sash“ to your kernel command line – be it lilo or grub. This way, you will be directly dropped into a sash session.
What’s missing?
Sadfully one essential command is missing: fsck. As the sash manual points out: fsck is just way too big to be included in a statically linked binary. Sad, but true. But hey: Better being to able at least to act on the console than having no console at all.
Sash as a standard shell?
… is not a good idea. It just lacks a lot of features you’ll really want when working on the command line: A verbose prompt, command history, tab completion and so on.
So it’s to install sash now as you will miss it, when it’s too late 
(And just if you’d like to ask: Yes, at least once I really needed sash and it helped me to save a lot of time.)